Original Link: https://www.anandtech.com/show/12585/the-nvidia-gtc-2018-keynote-live-blog
The NVIDIA GTC 2018 Keynote Live Blog
by Ryan Smith & Nate Oh on March 27, 2018 11:50 AM EST
12:02PM EDT - I'm here at the San Jose Convention Center for NVIDIA's 2018 GPU Technology Conference
12:03PM EDT - Kicking off this first full day of events is of course NVIDIA CEO Jen-Hsun Huang's keynote address, which always moves fast and is packed with major NVIDIA announcements
12:04PM EDT - The show is set to start at 9am, but it typically runs 10 minutes or so late
12:05PM EDT - Jen-Hsun has taken away the tables for the press this year, so we're all doing this on lap-tops, literally
12:05PM EDT - And here we go
12:07PM EDT - It's a long song, it seems
12:07PM EDT - “This is the greatest show”
12:08PM EDT - Joining me remotely today is AnandTech GPU Editor Nate Oh, who is covering photos
12:08PM EDT - WiFi connectivity at GTC is always spotty. But this year is proving worse than most
12:10PM EDT - Okay, and now the song is over and a video is rolling
12:10PM EDT - I think this may be an updated version of last year's video?
12:12PM EDT - "I am AI"
12:12PM EDT - And Jen-Hsun has now taken the stage
12:14PM EDT - Today's topics: amazing graphics, amazing science, amazing AI, and amazing robots
12:14PM EDT - First topic: graphics
12:14PM EDT - Looks like we're starting with photorealism and ray tracing

12:15PM EDT - (Captain Phasma may not have done anything of importance in the movies, but she sure shows up a lot in ray tracing talks thanks to that reflective chrome suit)
12:16PM EDT - Jen-Hsun is noting the amount of compute time required to render a single image for a film, never mind all of the frames
12:17PM EDT - NVIDIA wants to further close the gap between rasterization and ray tracing

12:18PM EDT - Jen-Hsun is going over all the tricks currently used to fake lighting in games/rasterization. Pre-baked lighting, AO shaders, etc

12:19PM EDT - As opposed to real reflections, real transparencies, real global illumination, etc








12:25PM EDT - Sorry for the interruption. WiFi is trying its best to die
12:26PM EDT - Jen-Hsun and his tech are going over everything involved in the Star Wars ray tracing tech demo from last week

12:27PM EDT - NVIDIA and ILM do this in real time on a single DGX Station. So 4 GPUs
12:27PM EDT - Confirming that this is in real time, moving the camera around to prove it
12:28PM EDT - Announcing NVIDIA RTX technology
12:28PM EDT - Perhaps we'll get a more hardware-focused look at last week's RTX announcement?
12:29PM EDT - Announciung Quadro GV100


12:30PM EDT - API support: DirectX Raytracing, NVIDIA OptiX, and Vulkan
12:30PM EDT - Quadro GV100 is the "world's largest GPU"
12:31PM EDT - (It looks like the same size as always)
12:31PM EDT - Confirming NVLink 2 support. 2 connectors on the board
12:31PM EDT - Discussing how two GV100 cards can be teamed together, including shared memory pools

12:32PM EDT - 5120 CUDA cores. 640 tensor cores
12:32PM EDT - 32GB of HBM2 memory

12:33PM EDT - Now back to rendering technology



12:37PM EDT - “The more GPUs to buy, the more money you save”
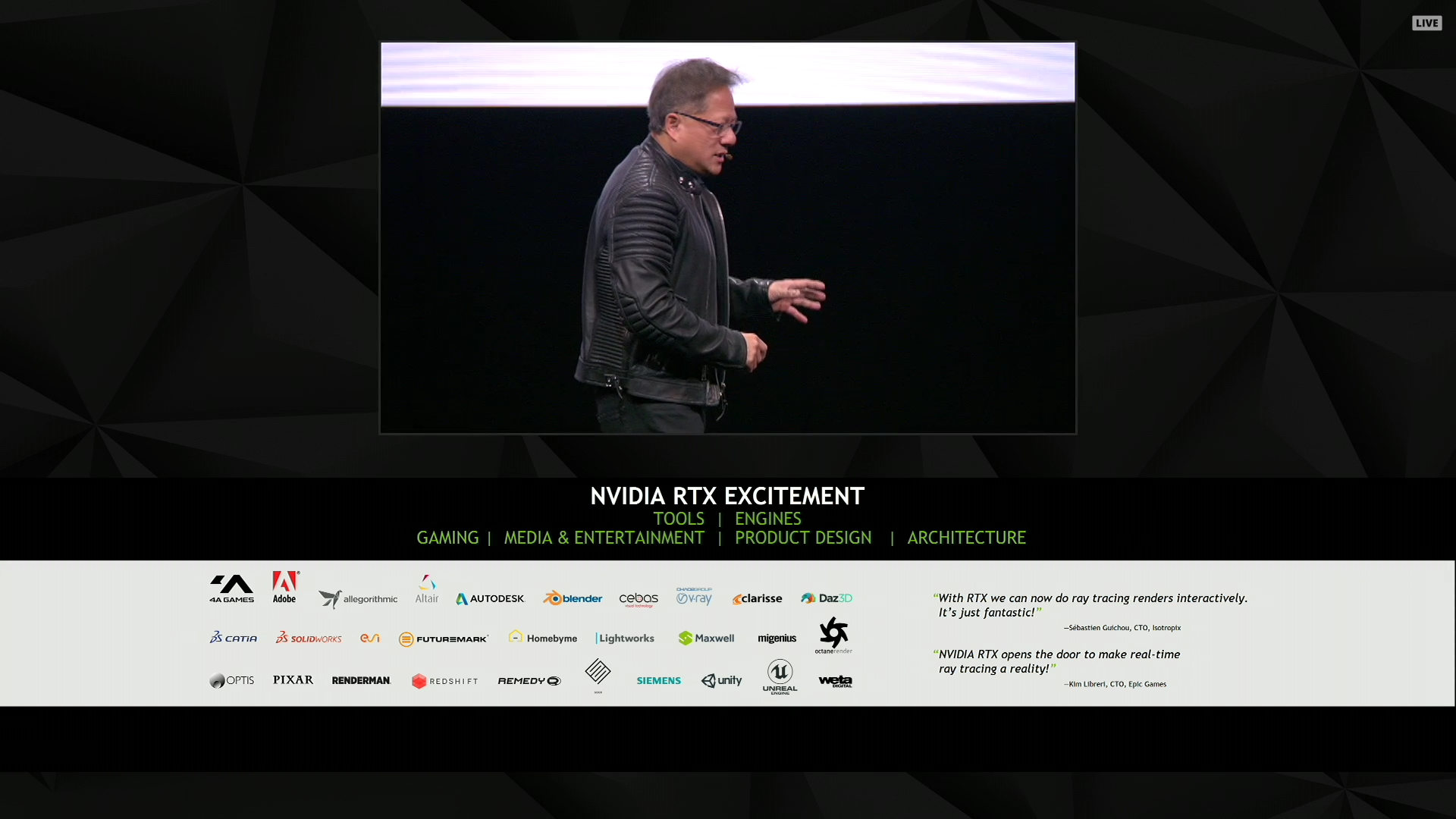
12:38PM EDT - Discussing the cost benefits of GPU rendering versus a large CPU farm
12:38PM EDT - Now talking about the rise of GPU computing
12:39PM EDT - Discusisng how GPU's have become much more flexible over the years
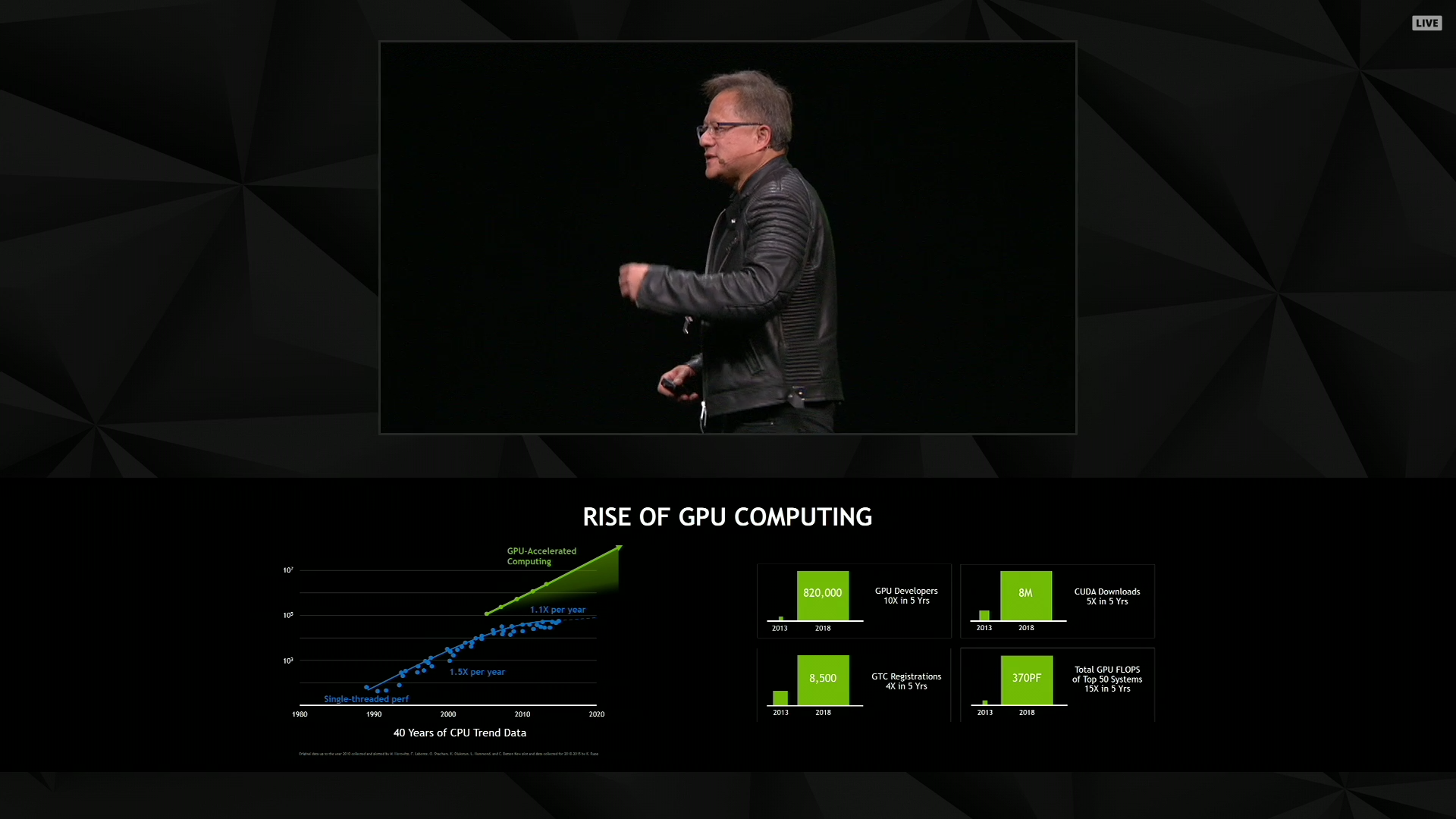
12:40PM EDT - "We're at the tipping point": of GPU computing
12:41PM EDT - The SJC Convention Center is a packed house. 8500 registrations
12:42PM EDT - "The world needs larger computers"
12:43PM EDT - Recapping various supercomputers and what projects they've worked on

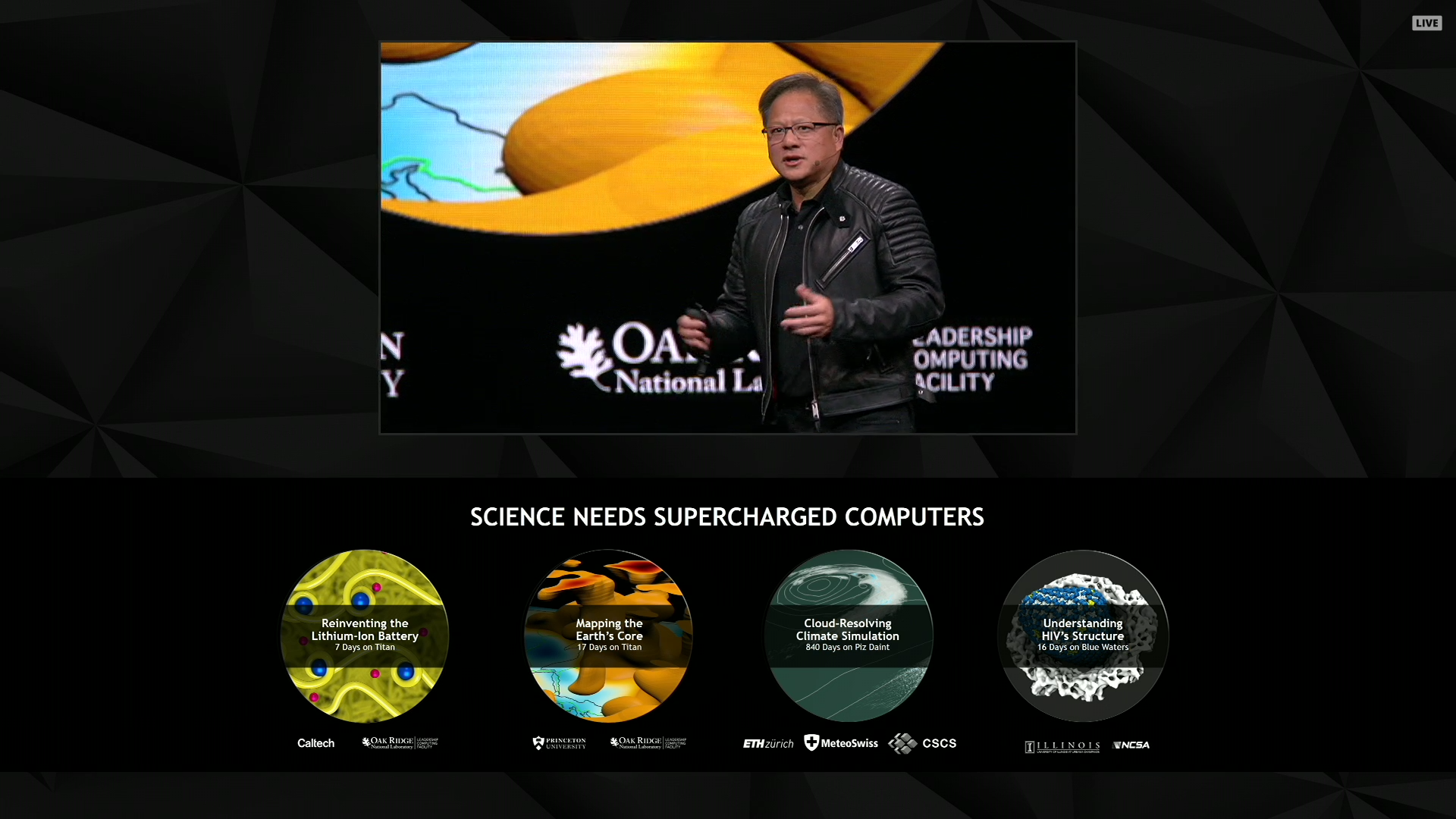
12:44PM EDT - Fermi vs. Volta

12:45PM EDT - This is supposed to be a 5 year comparison, but I'd note that the Kepler-based Tesla K20 launched more than 5 years ago
12:46PM EDT - Moral of the story? GPU perf has thus far grown faster than Moore's Law (in most case)



12:50PM EDT - "The more you buy, the more you save" once again. This time reflecting the pace of the Tesla line and Volta V100 servers
12:50PM EDT - (WiFi gets overloaded, dies, dumps the problem machines, and comes back)
12:50PM EDT - Now talking about medical applications of GPU computing via medical imaging

12:52PM EDT - NVIDIA Project Clara. A "medical imaging supercomputer"
12:54PM EDT - Demo time
12:54PM EDT - EKG of a heart
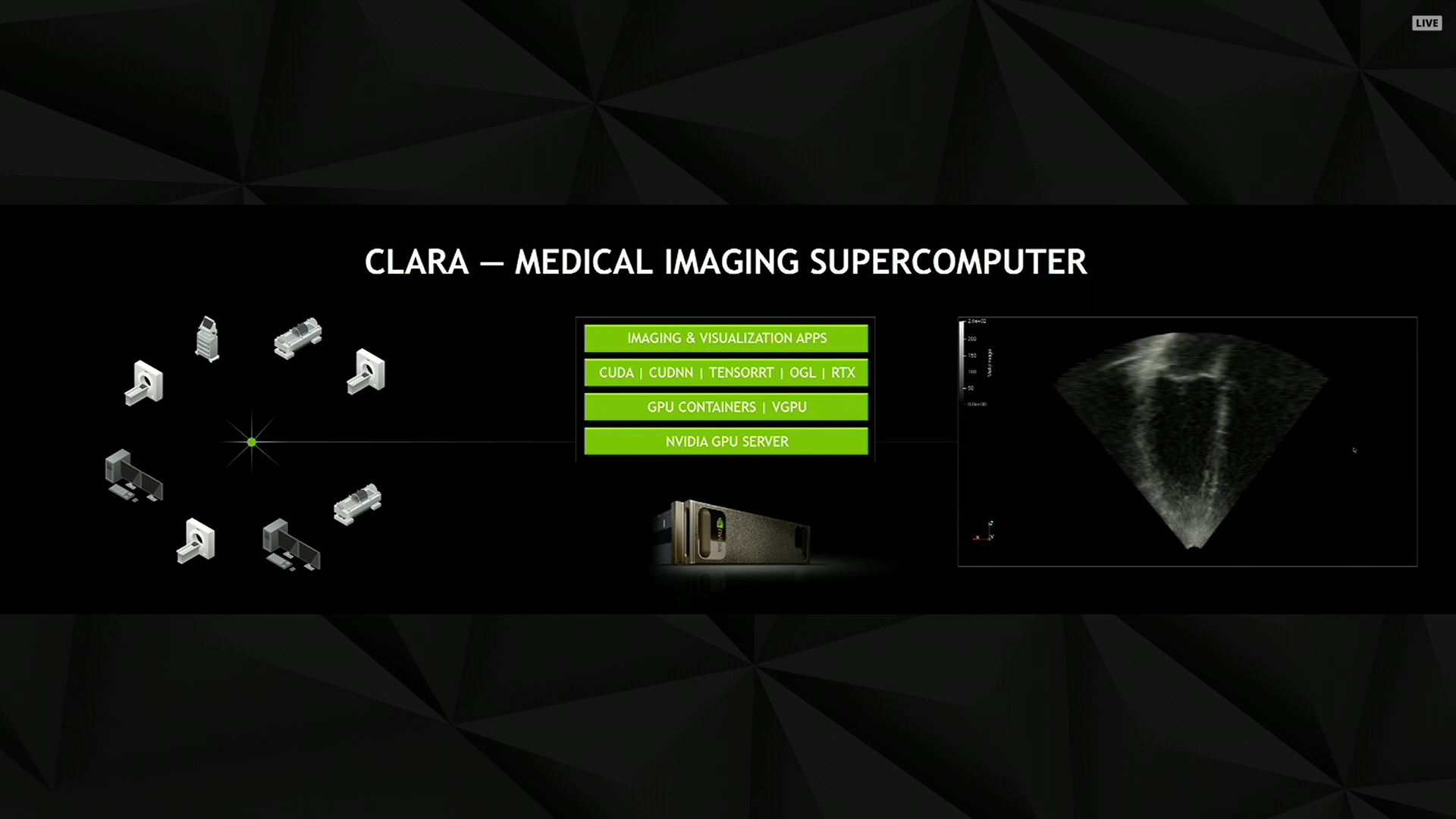
12:55PM EDT - Showing how NVIDIA is taking the scan data off of a 15 year old machine and enhancing the resulting imagery
12:55PM EDT - Using algorithms to produce a volumetric representation
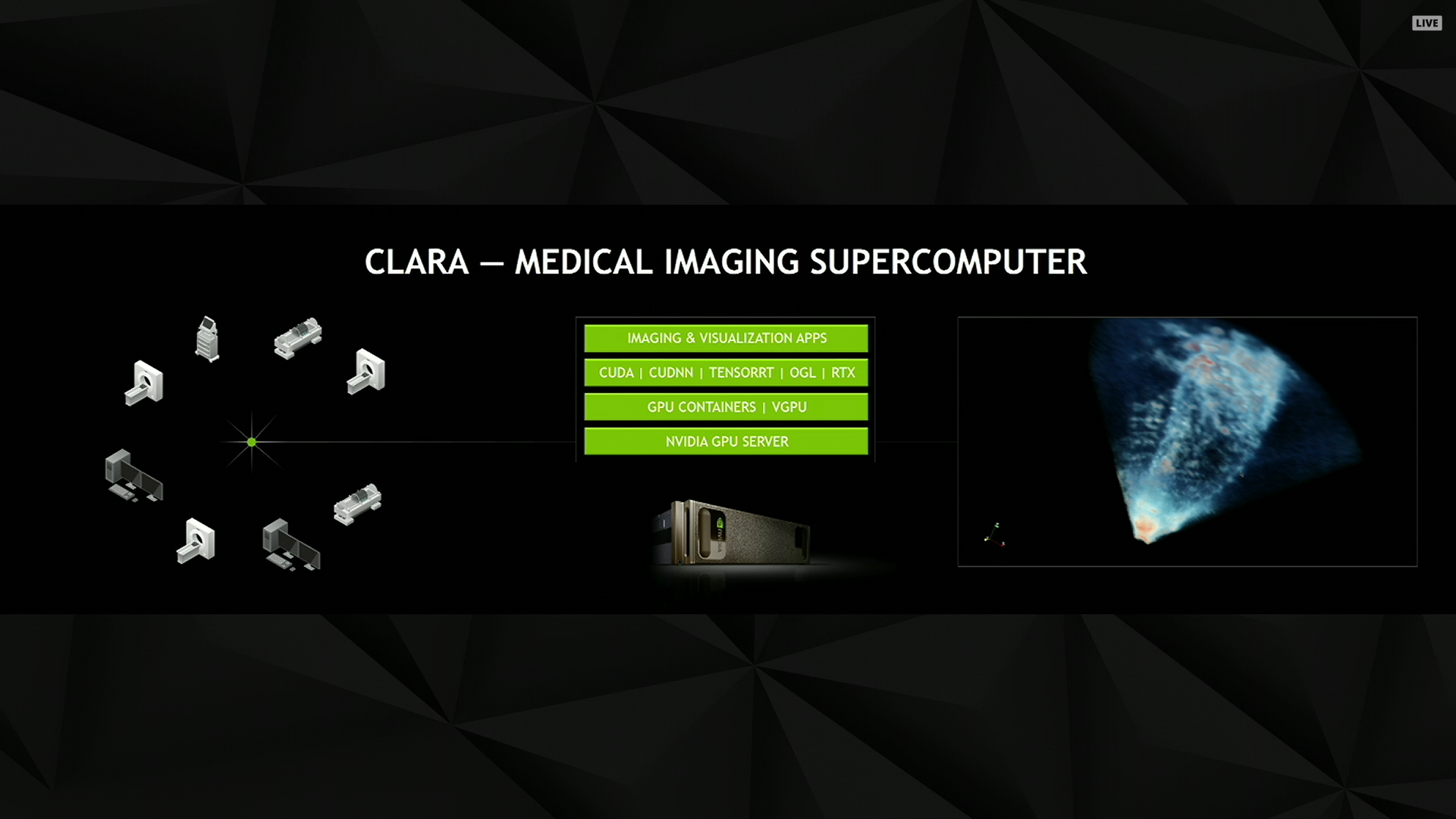
12:56PM EDT - Inferring where the left ventrical is in 3D basedon the 2D data
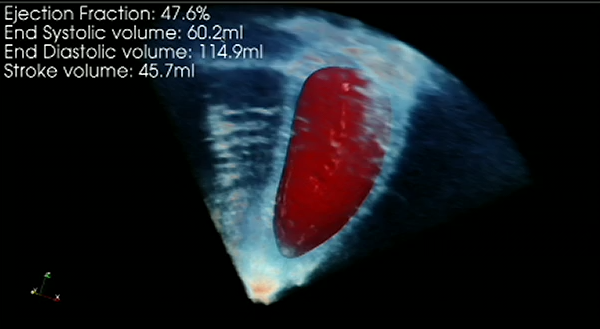
12:58PM EDT - Medical instruments have a long life cycle. NVIDIA wants to increase their usefulness by post-processing the data on GPUs to infer more data from the scans
12:59PM EDT - Shifting gears to AI

01:00PM EDT - "Deep learning has revolutionized modern AI"

01:01PM EDT - NVIDIA is doing everything they can to expand the platform (and capture the market)
01:03PM EDT - Volta V100 is getting a memory bump to 32GB of HBM2 per card
01:03PM EDT - Available now
01:03PM EDT - DGXs are getting the upgraded cards as well

01:03PM EDT - This isn't a new SKU to sit beside the 16GB SKUs. Tesla V100 is being replaced with 32GB cards in the market wholesale

01:05PM EDT - "The world wants a gigantic GPU"
01:05PM EDT - "The world's largest GPU"
01:05PM EDT - This is definitely a misnomer
01:05PM EDT - 16 Tesla V100s in a cluster together
01:06PM EDT - All connected together via a new item called the NVSwitch

01:06PM EDT - Unified memory space
01:06PM EDT - So this is all 16 cards in one system

01:07PM EDT - Aggregate HBM2 capacity of 512GB
01:07PM EDT - 2 PFLOPs
01:07PM EDT - That's 2 PFLOPs of tensor core throughput
01:09PM EDT - A new NVIDIA DGX server. "The world's largest GPU"
01:09PM EDT - NVSwitch has wB transistors, made on TSMC 12nm FFN
01:10PM EDT - 18 NVLInk ports per switch
01:10PM EDT - 900GB of full duplex bandwidth on a switch

01:10PM EDT - 12 switches on the new server
01:10PM EDT - Every GPU can communicate at 300GB/sec. 20x the bandwidth of PCIe
01:11PM EDT - "It's not a network. It's a switch" a fabric, to be precise
01:11PM EDT - So all the NVLink benefits of shared memory, coherency, etc are retained

01:11PM EDT - DGX-2
01:11PM EDT - 8x EDR IB/100 GigE

01:11PM EDT - 10 Kilowatt power consumption!
01:12PM EDT - 350 lbs
01:12PM EDT - 16 V100s backed by a pair of Xeon Platinum CPUs

01:12PM EDT - "No human can lift it"
01:14PM EDT - Uses a new NVLink plane card to connect two trays of Tesla V100s


01:16PM EDT - “This is what an engineer finds beautiful”
01:16PM EDT - (NV apparently filmed the blow-apart animation using stop-motion rather than CGI. Why? Because they could)
01:16PM EDT - 10x faster than DGX-1 in 6 months

01:17PM EDT - How much should we charge?
01:18PM EDT - Answer: $1,500,000
01:18PM EDT - Available in Q3
01:18PM EDT - Oh, no, $1.5M was a joke
01:18PM EDT - $399K is the real price



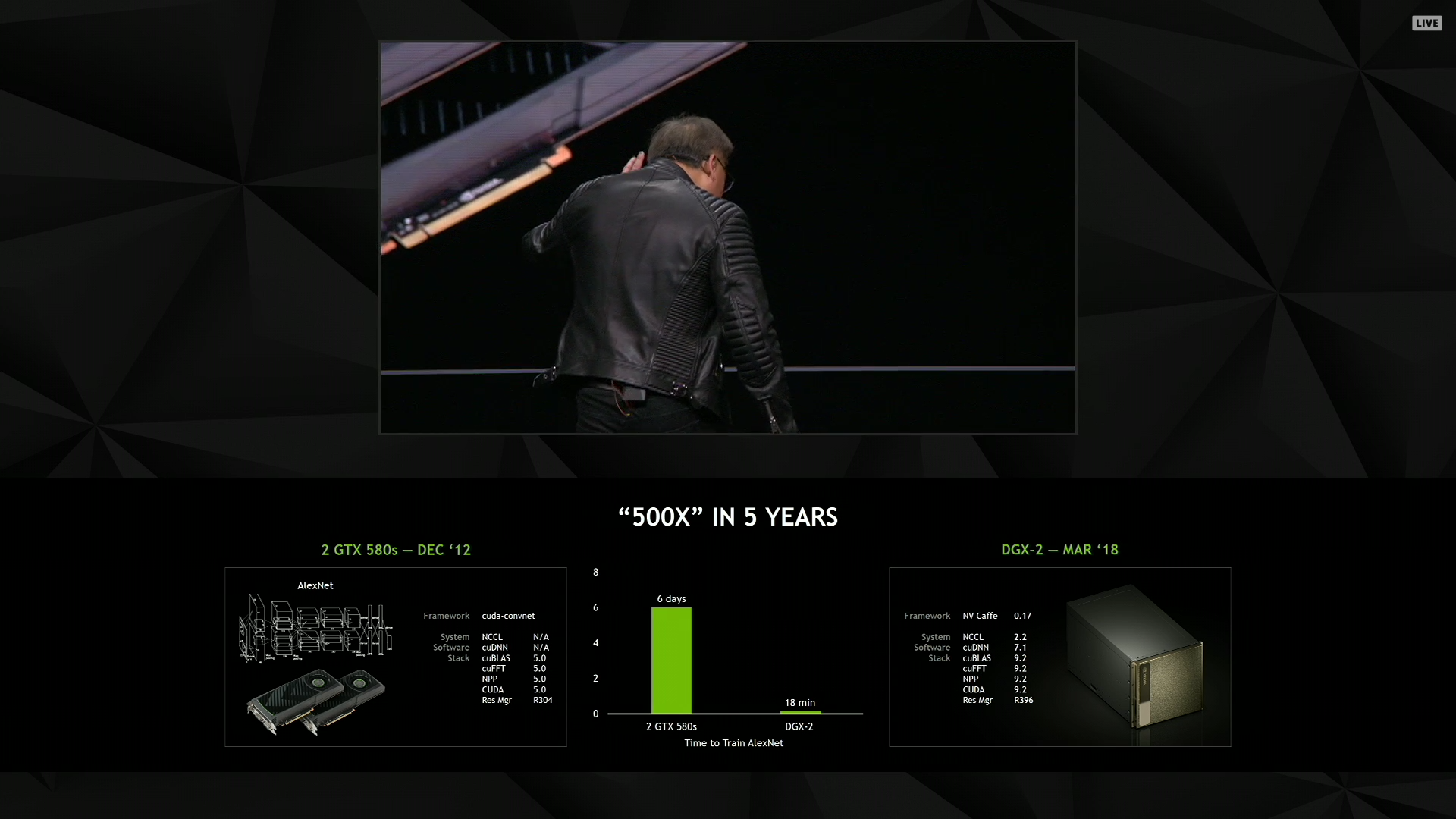
01:22PM EDT - "We are all in on deep learning"
01:22PM EDT - Comparing AlexNet training time on the GTX 580 versus the DGX-2
01:22PM EDT - Days versus minutes
01:23PM EDT - Now talking about NVIDIA's software container service, the NVIDIA GPU Cloud
01:24PM EDT - 30 different containers
01:24PM EDT - Google, Alibaba, AWS, and more support the containers

01:25PM EDT - "Plaster"
01:26PM EDT - "We need a computing model that dramatically reduces the energy requirements"

01:29PM EDT - “Inference is complicated”
01:29PM EDT - (This is an understatement, to ssy the least)

01:30PM EDT - Announcing a new batch of tools and libraries
01:30PM EDT - TensorRT 4.0
01:30PM EDT - Deep TensorFlow integration
01:31PM EDT - A fully trained network can be run right on NV's architecture in an optimized fashion
01:31PM EDT - TensorRT also adds support for the Onyx format and WinML
01:33PM EDT - Now discussing the various acceleration factors versus CPU-only execution
01:33PM EDT - (They're all big integers)
01:34PM EDT - "We're going to save a lot of money"

01:34PM EDT - Kubernetes on NVIDIA GPUs
01:34PM EDT - IMost people here don't know what Kubernetes is)
01:35PM EDT - An orchestration layer to allocate work over a datacenter
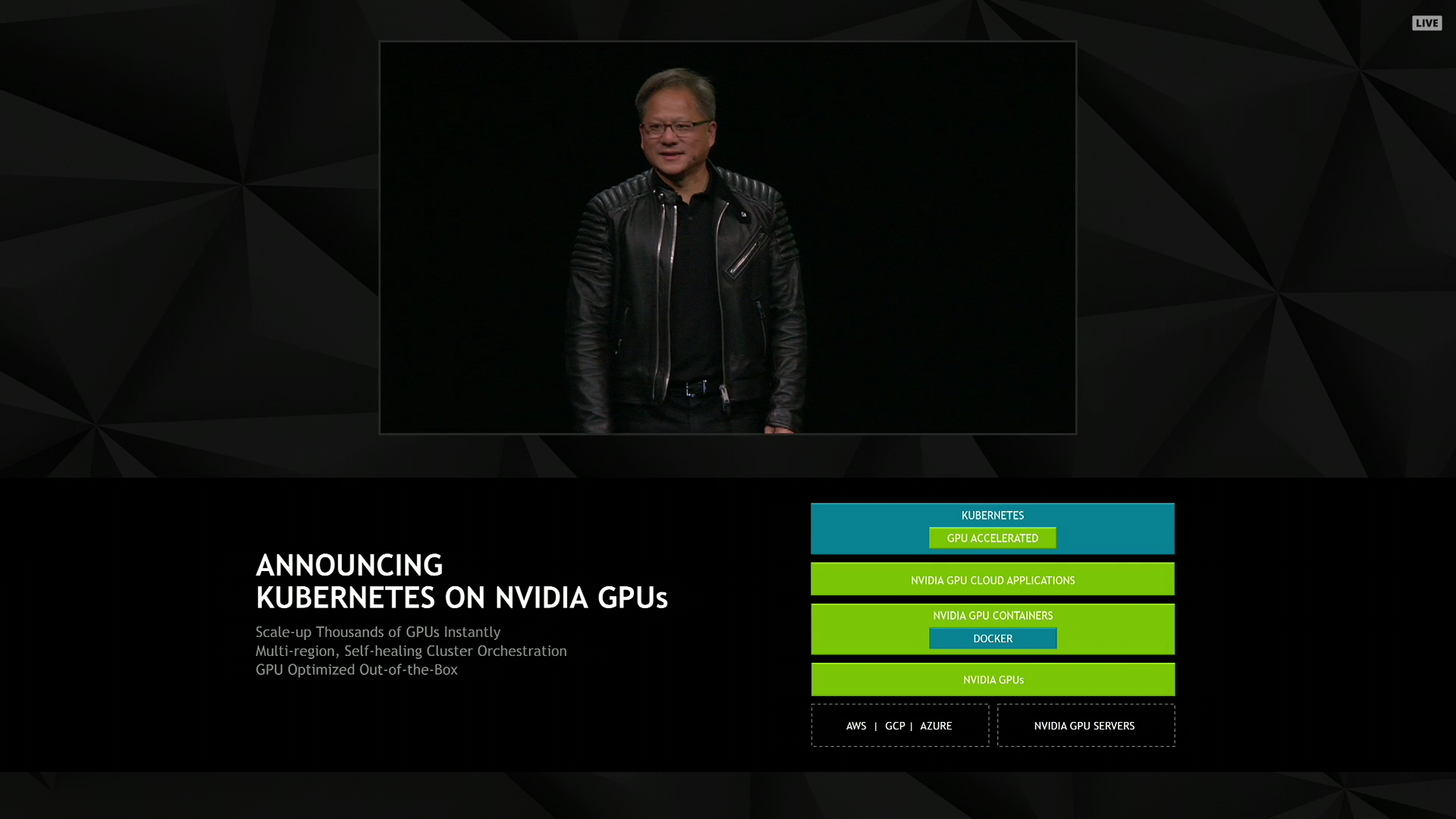
01:36PM EDT - Kubernetes is now GPU-aware, allowing large tasks to be allocated over multiple servers and supported at multiple cloud services
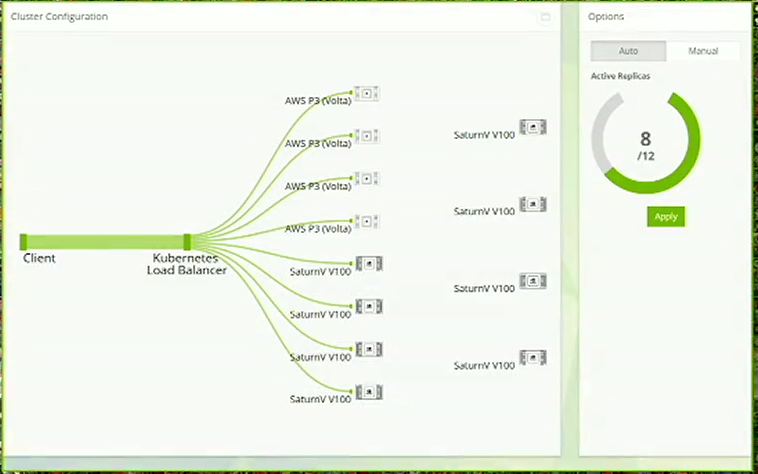
01:38PM EDT - Demoing TensorRT on one V100
01:38PM EDT - Now on 8 servers via Kubernetes in real time


01:39PM EDT - Not an 8x speedup, but still a lot faster

01:40PM EDT - Saturn V is up to 660 DGX-1 nodes
01:41PM EDT - Saturn V is up to 660 DGX-1 nodes
01:42PM EDT - Demoing resiliency
01:43PM EDT - And that's a wrap on AI inference

01:44PM EDT - Titan V is still officailly out of stock
01:44PM EDT - NV is working on it

01:45PM EDT - Now heaping praise on the NVIDIA Research group

01:46PM EDT - JHH's favorite project? Noise-to-noise denoising of ray tracing
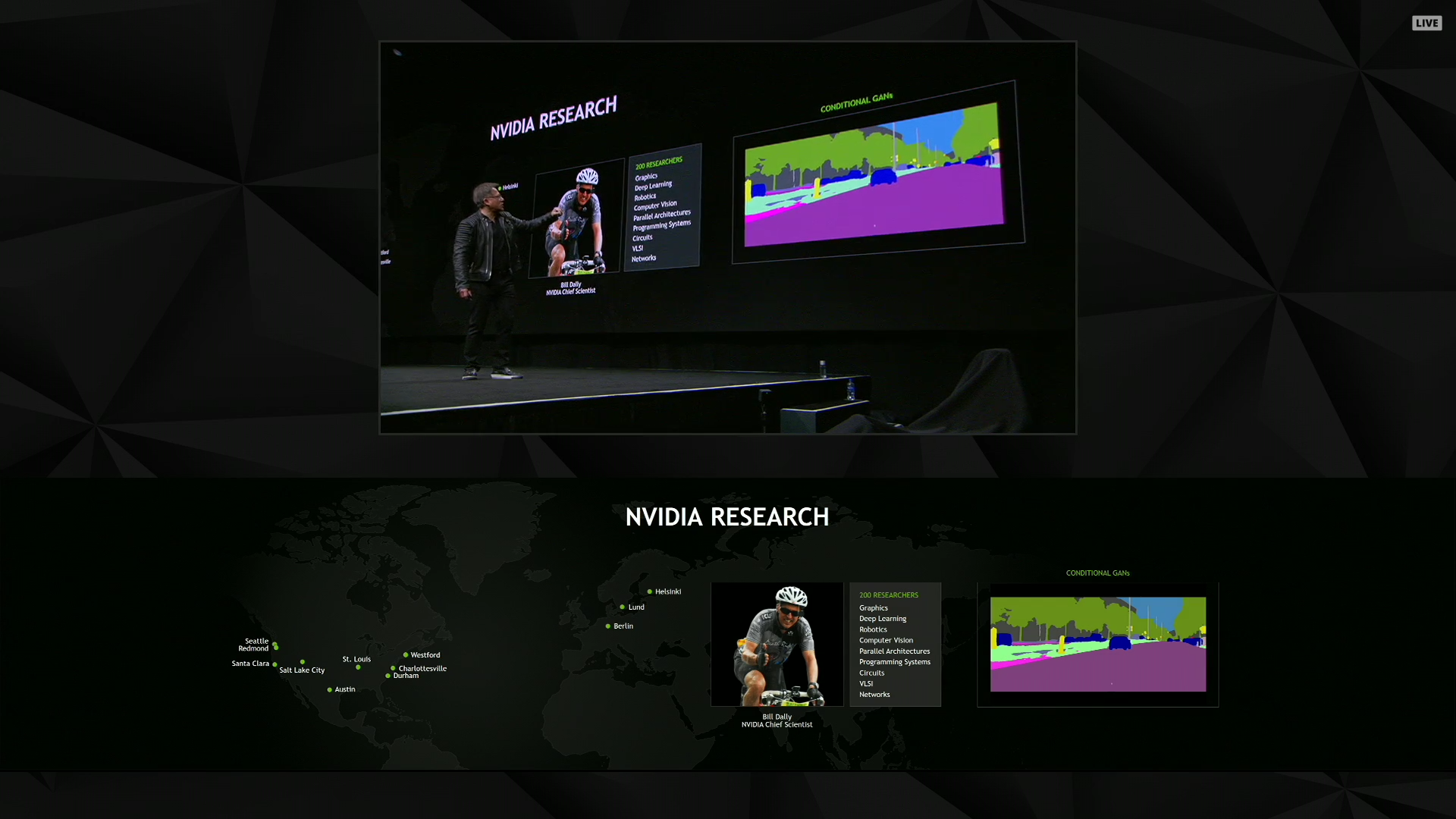
01:48PM EDT - Another project: using GANs to synthesize realistic environments

01:50PM EDT - And now time to talk about autonomy and NV's self-driving projects

01:50PM EDT - "It's hard, it's really, really hard"
01:50PM EDT - But "this work is vitally important" as well
01:52PM EDT - Sensor fusion can overcome the limitations of individual sensor types
01:52PM EDT - But it's a hard problem. One that NV is working on
01:53PM EDT - Recapping the DRIVE platform and the end-to-end training process

01:54PM EDT - Recapping the DRIVE platform and the end-to-end training process
01:55PM EDT - “Simulation is going to be the foundation of success”
01:55PM EDT - The NVIDIA Perception Infrastructure
01:55PM EDT - Labeling 1mil images per month
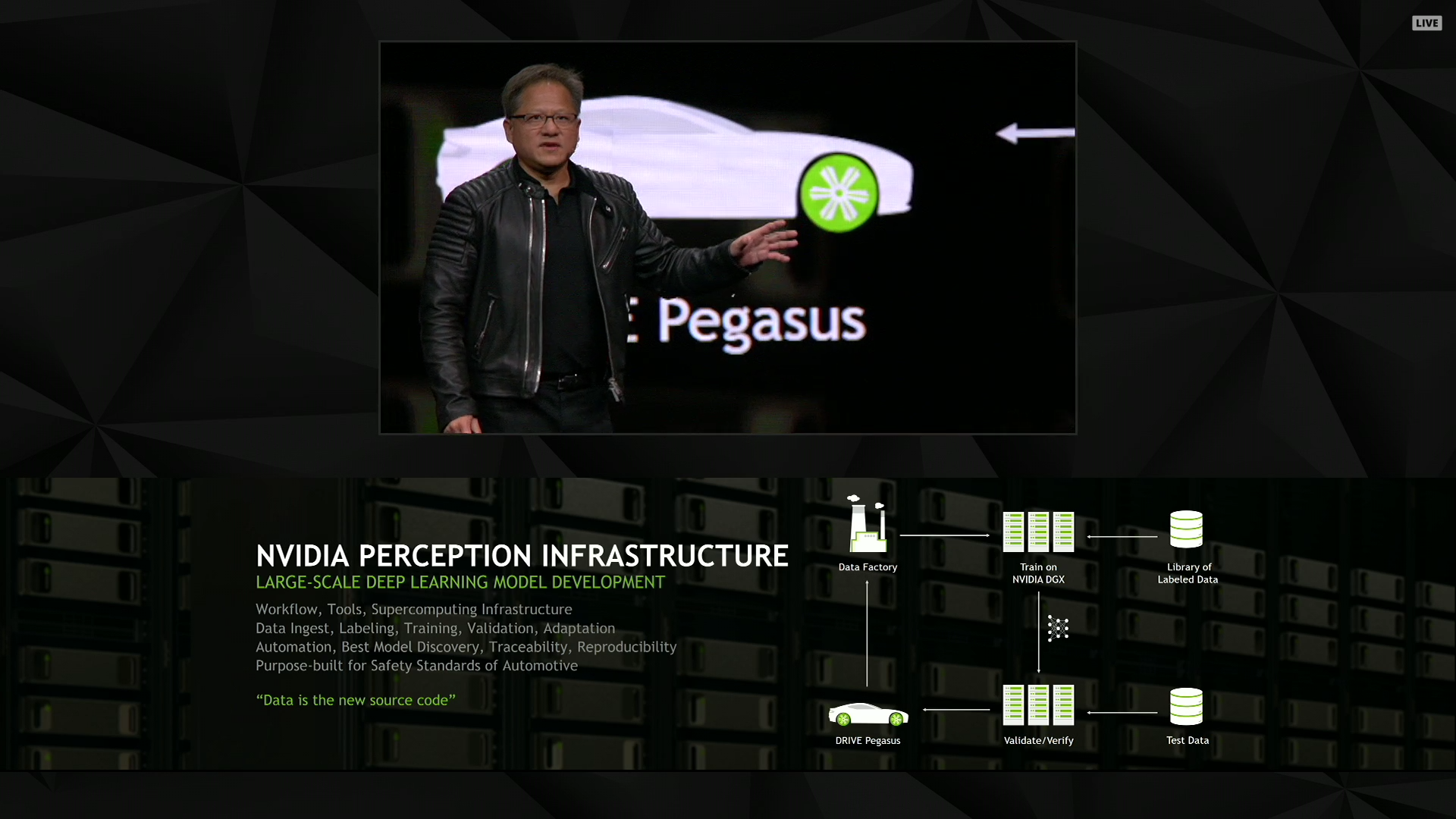
01:56PM EDT - The end product of the system is networks
01:58PM EDT - (Ultimately this seems to be NV's response to last week's self-driving Uber incident)
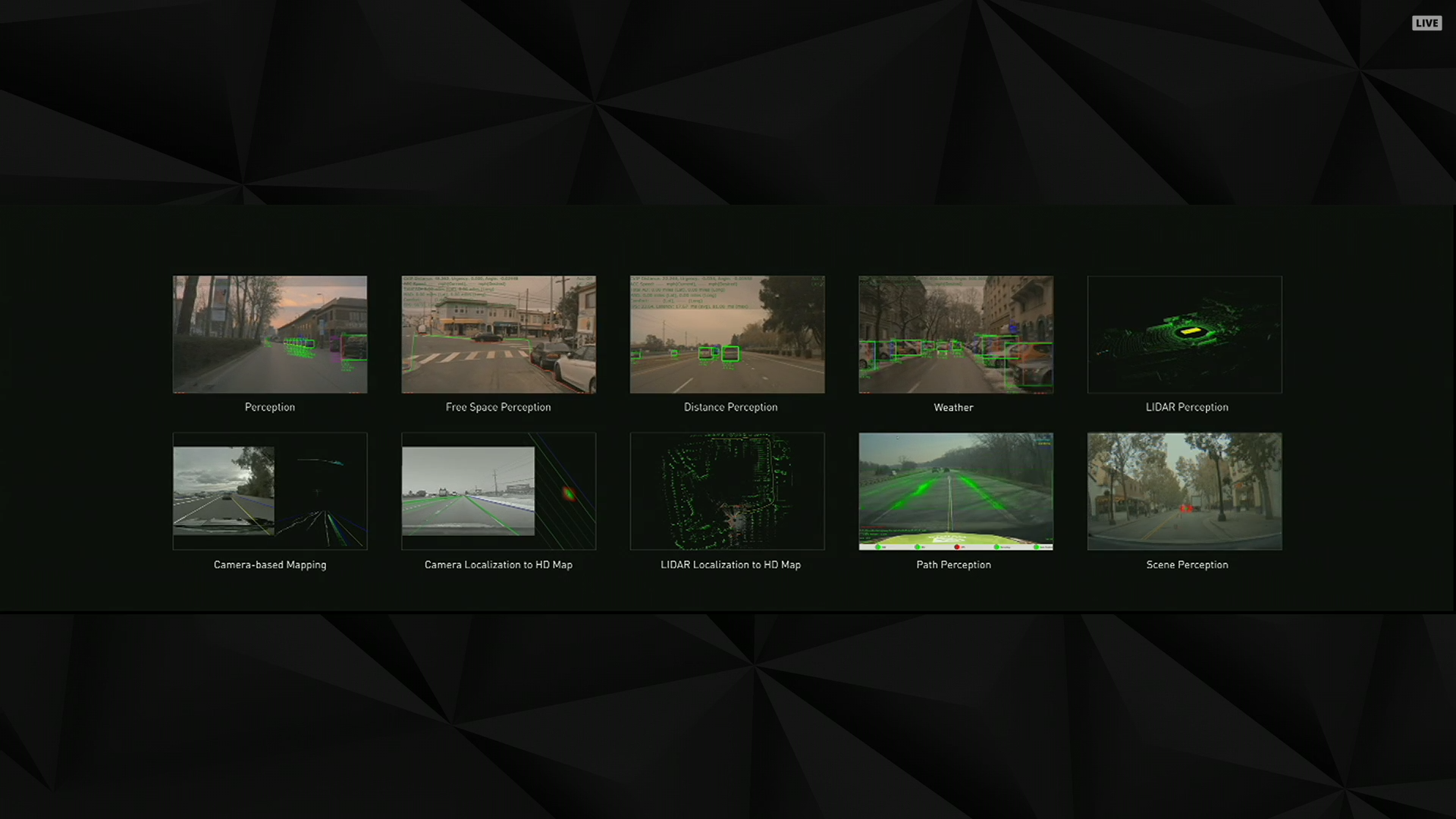
01:58PM EDT - (Which, I hear from a source, was using NVIDIA DRIVE hardware; no idea whose algorithms though)
02:00PM EDT - All cars are mapping cars
02:01PM EDT - "We're going to work on this for another 2 or 3 years before we ship in volume cars"
02:01PM EDT - Now rolling a video



02:07PM EDT - Monitoring not only the car but the passengers as well
02:08PM EDT - Recapping the DRIVE hardware roadmap
02:09PM EDT - Both Xavier and Pegasus in production by the end of the year
02:09PM EDT - ASIL-D functional safety
02:10PM EDT - "We're not stopping here"
02:10PM EDT - Next generation DRIVE: Orin
02:11PM EDT - Get Pegasus down to a couple of small Orins
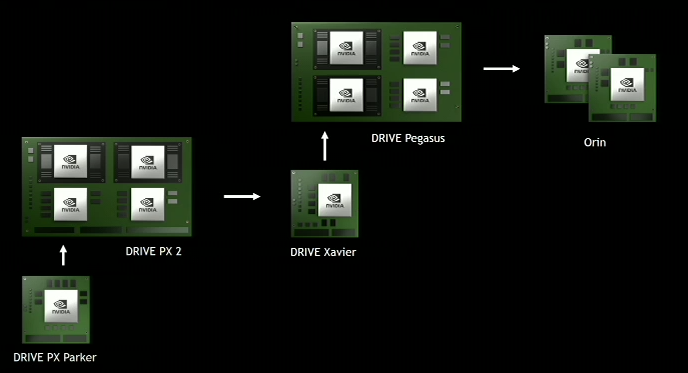

02:13PM EDT - Jen-hsun is now making the point that it would take many thousands of test cars to get to a fraction of the real world miles driven by humans
02:13PM EDT - Which makes it hard to do enough testing
02:13PM EDT - The solution? Simulation
02:14PM EDT - This looks to be a continuation of NV's simulation-driven training program revealed at GTC 2017
02:15PM EDT - The simulation needs to offer enough fidelity to properly tax the sensors

02:16PM EDT - Now showing the DRIVE system view

02:18PM EDT - Can use the artificial nature of the sim to ensure weird, atypical situations are much more frequent than in real life

02:20PM EDT - NVIDIA DRIVE Sim and Constellation, an AV validation system
02:20PM EDT - 10K Constallations drive 3B miles per year
02:22PM EDT - 370 partners on DRIVE
02:22PM EDT - Cars are the first, but robots are coming

02:23PM EDT - (Jen-Hsun is running long)
02:23PM EDT - NVIDIA will be relasing their Isaac robotics platofrm, first introduced at GTC 2017


02:24PM EDT - Rolling video

02:28PM EDT - One last thing. NV is demoing using VR to take control of an autonomous car
02:28PM EDT - This is a live demo
02:29PM EDT - The car is out back. The driver is on the stage



02:31PM EDT - This has been a sci-fi staple for years. But it still looks cool



02:33PM EDT - VR + Autonomous machines = teleportation
02:33PM EDT - Now recapping the keynote

02:36PM EDT - And that's a warp. Off to Q&A. Thanks for joining us.






